export data from redshift to s3|Export data from AWS Redshift to AWS S3 : Pilipinas Data import and export from data repositories is a standard data administration process. From developers to administrators, almost everyone has a need to extract the data from database management systems. In the AWS Data Lake concept, AWS S3 is the data storage layer and Redshift is the . Tingnan ang higit pa bet365 - L'azienda leader nel settore del gioco online. Offriamo il servizio in Tempo Reale più completo. Segui lo Sport Live. Diretta TV a disposizione su PC, telefonino e tablet. Scommetti sullo Sport. Scommetti subito sugli Sport, inclusi Calcio, Tennis e Pallacanestro.
PH0 · Unloading data to Amazon S3
PH1 · Unloading a file from Redshift to S3 (with headers)
PH2 · Unloading Data from Redshift to S3 – Data Liftoff
PH3 · UNLOAD
PH4 · Tutorial: Loading data from Amazon S3
PH5 · Scheduling data extraction from AWS Redshift to S3
PH6 · Export data from AWS Redshift to AWS S3
PH7 · Export JSON data to Amazon S3 using Amazon Redshift UNLOAD
PH8 · Amazon Redshift to S3: 2 Easy Methods
PH9 · 4 methods for exporting CSV files from Redshift
Biography. Gianna Dior was born on 12 May 1997 in California, United States. She held a deep fascination for the film and modelling industry from a young age. . participating in various modelling photo shoots and seizing opportunities to work alongside distinguished actors like Anna Ralphs and Simonn. Name: Gianna Dior: Alternative Name .
export data from redshift to s3*******Data import and export from data repositories is a standard data administration process. From developers to administrators, almost everyone has a need to extract the data from database management systems. In the AWS Data Lake concept, AWS S3 is the data storage layer and Redshift is the . Tingnan ang higit paIn this article, it’s assumed that a working AWS Redshift cluster is in place. Redshift beginners can refer to this article, Getting started with AWS Redshift, to create a new AWS . Tingnan ang higit paIn this article, we learned how to use the AWS Redshift Unload command to export the data to AWS S3. We also learned the different . Tingnan ang higit paexport data from redshift to s3 Export data from AWS Redshift to AWS S3 Amazon Redshift splits the results of a select statement across a set of files, one or more files per node slice, to simplify parallel reloading of the data. Alternatively, you can .You can unload the result of an Amazon Redshift query to your Amazon S3 data lake in Apache Parquet, an efficient open columnar storage format for analytics. Parquet format . You can use this feature to export data to JSON files into Amazon S3 from your Amazon Redshift cluster or your Amazon Redshift Serverless endpoint to make . The basic syntax to export your data is as below. UNLOAD ('SELECT * FROM your_table') TO 's3://object-path/name-prefix' IAM_ROLE 'arn:aws:iam:::role/
' CSV; On . Method 1: Unload Data from Amazon Redshift to S3 using the UNLOAD command. Method 2: Unload Data from Amazon Redshift to S3 in Parquet Format. . Define pipeline with the following components: SQLDataNode and S3DataNode. SQLDataNode would reference your Redshift database and SELECT .The COPY command uses the Amazon Redshift massively parallel processing (MPP) architecture to read and load data in parallel from multiple data sources. You can load .
A few days ago, we needed to export the results of a Redshift query into a CSV file and then upload it to S3 so we can feed a third party API. Redshift has already .
The UNLOAD command is quite efficient at getting data out of Redshift and dropping it into S3 so it can be loaded into your application database. Another common .export data from redshift to s3How to Export Data from Redshift. The COPY command is the most common and recommended way for loading data into Amazon Redshift. Similarly, Amazon Redshift has the UNLOAD command, which can be used to unload the result of a query to one or more files on Amazon S3. The data is unloaded in CSV format, and there’s a number of .
I'm trying to move a file from RedShift to S3. Is there an option to move this file as a .csv? Currently I am writing a shell script to get the Redshift data, save it as a .csv, and then upload to S3. I'm assuming since this is all on AWS services, they would have an argument or something that let's me do this. I would like to unload data files from Amazon Redshift to Amazon S3 in Apache Parquet format inorder to query the files on S3 using Redshift Spectrum. I have explored every where but I couldn't find . Just to clarify - the blogpost mentioned is about copying INTO Redshift, not out to S3. – mbourgon. Commented Sep 24, 2019 at 16:01. . Read data from Amazon S3, and transform and load it into Redshift Serverless. Save the notebook as an AWS Glue job and schedule it to run. Prerequisites. For this walkthrough, we must complete the following prerequisites: Upload Yellow Taxi Trip Records data and the taxi zone lookup table datasets into Amazon S3. Steps to do that . Step 2: Source Data Capture Setup. Once you’ve logged in, locate the Captures option on the left side of the Estuary dashboard. On the Captures page, click on the New Capture button. This step is to set up the source end of the data pipeline. Search for S3 in Source Connectors. Then, click on the Capture button.
Method 2: Using AWS Services to Connect Amazon S3 to Redshift. AWS offers a number of services that can be used to perform data load operations to Redshift Data Warehouse. AWS Glue and AWS Data pipeline are 2 such services that enable you to transfer data from Amazon S3 to Redshift. Method 3: Using Hevo’s No Code Data .Amazon Redshift To Amazon S3 transfer operator. This operator loads data from an Amazon Redshift table to an existing Amazon S3 bucket. To get more information about this operator visit: RedshiftToS3Operator. Example usage: You can find more information to the UNLOAD command used here. Navigate to the editor that is connected to Amazon Redshift. One of the default methods to copy data in Amazon Redshift is the COPY command. This command provides various options to configure the copy process. We would look at the key ones that will allow us to copy the CSV file we have hosted on the Amazon S3 bucket.
Spark streaming back into s3 using Redshift connector; UNLOAD into S3 gzipped then process with a command line tool; Not sure which is better. I'm not clear on how to easily translate the redshift schema into something parquet could intake but maybe the spark connector will take care of that for me. ETL (Extract, Transform, Load) Job : An ETL job is a data integration process that involves three main stages; Extract: Retrieving data from one or more sources, such as databases, files, or APIs .
I am trying to extract data from AWS redshift tables and save into s3 bucket using Python . I have done the same in R, but i want to replicate the same in Python . Here is the code I am using R drv. There appears to be 2 possible ways to get a single file: Easier: Wrap a SELECT .. LIMIT query around your actual output query, as per this SO answer but this is limited to ~2 billion rows. Harder: Use the Unix cat utility to join the files together cat File1.txt File2.txt > union.txt. After using Integrate.io to load data into Amazon Redshift, you may want to extract data from your Redshift tables to Amazon S3. There are various reasons why you would want to do this, for example: You want to load the data in your Redshift tables to some other data source (e.g. MySQL) To better manage space in your Redshift cluster, .
Data Lake Export to unload data from a Redshift cluster to S3 in Apache Parquet format, an efficient open columnar storage format optimized for analytics. Federated Query to be able, from a Redshift cluster, to query across data stored in the cluster, in your S3 data lake, and in one or more Amazon Relational Database Service .
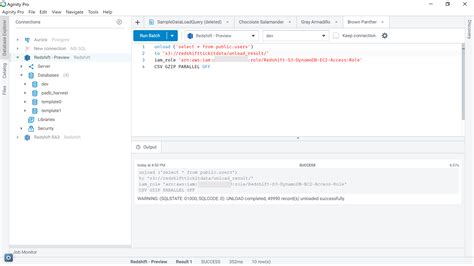
s3_key='redshift_data.csv', access_key=credentials.access_key, secret_key=credentials.secret_key) To me your SQL query seems syntactically incorrect, if its not typo. SELECT * FROM (SELECT * FROM mytable LIMIT 10); as @RedBoy points out the query seems off. Everything else looks fine. Have you tried running this unload .
Generating the CREATE TABLE statement from DBeaver. 5. Using the COPY command. The COPY command allows you to move from many Big Data File Formats to Amazon Redshift in a short period of time .Before you export DB snapshot data to Amazon S3, give the snapshot export tasks write-access permission to the Amazon S3 bucket. To grant this permission, create an IAM policy that provides access to the bucket, then create an IAM role and attach the policy to the role. You later assign the IAM role to your snapshot export task.
This command connects to the PostgreSQL database and exports the data from the Customers_info table to the file named Customers_data.csv. You can use AWS Console or Amazon CLI to upload your exported CSV file to an Amazon S3 bucket. Step 3: Load the Data from S3 to Temporary Table in Redshift.
If you want to install Freemake Video Downloader to your computer without the Internet connection, download these files Freemake Video Downloader 3.8.5 Download now
export data from redshift to s3|Export data from AWS Redshift to AWS S3